
RD1234 - 2024.04.07

News
TSLA - Delivery远低于预期,把1月份公布的low cost model直接改为了robotaxi项目
INTC - 公布了foundry数据后大跌。要同时解决intel cpu和foundry规模两个问题,很难。唯一的优势就是TSM在台湾,而三星foundry也很糟。
AI - Coreweave强调需求不错,OpenAI的enterprise signup也在3个月内4倍。另一方面,预测未来缺乏training数据,模型优化可以节省一半资源。
AI Networking
Broadcom的这个slide让人感觉Networking下面的变化会很大

4年内从30k到1M,要翻30倍。而且这是网络,所以里面的增长都不是线性的。远远超过了Moore's Law。
另外,目前data center的供电极限就是30-60k个GPU,1M肯定会带来很多新的问题。所以下面要优化的不再是单个GPU,而是GPU集群,网络就会变得更加重要。
看一下Blackwell里面的networking
Blackwell内部,2个GPU的die连着一起
GPU to HBM,通过CoWoS实现
GPU to CPU,通过NVlink c2c实现
GPU to GPU,通过NVlink实现
Rack to Rack,Infiniband或者Ethernet
Broadcom在AI Event给出了一些对应的方案
不涉及
不涉及
PCIe
PCIe
Ethernet
可以看到主要的竞争在3-5。仔细看过Broadcom的presentation,觉得他们最有信心的是在5上面用Ethernet打败Infiniband。但是其实这个问题不重要,第一,Nvidia自己也有Ethernet的方案,第二,集群的优化从level 1开始,而不是level 5。这是Fabricated Knowledge最近文章里面一个很有意思的图表。
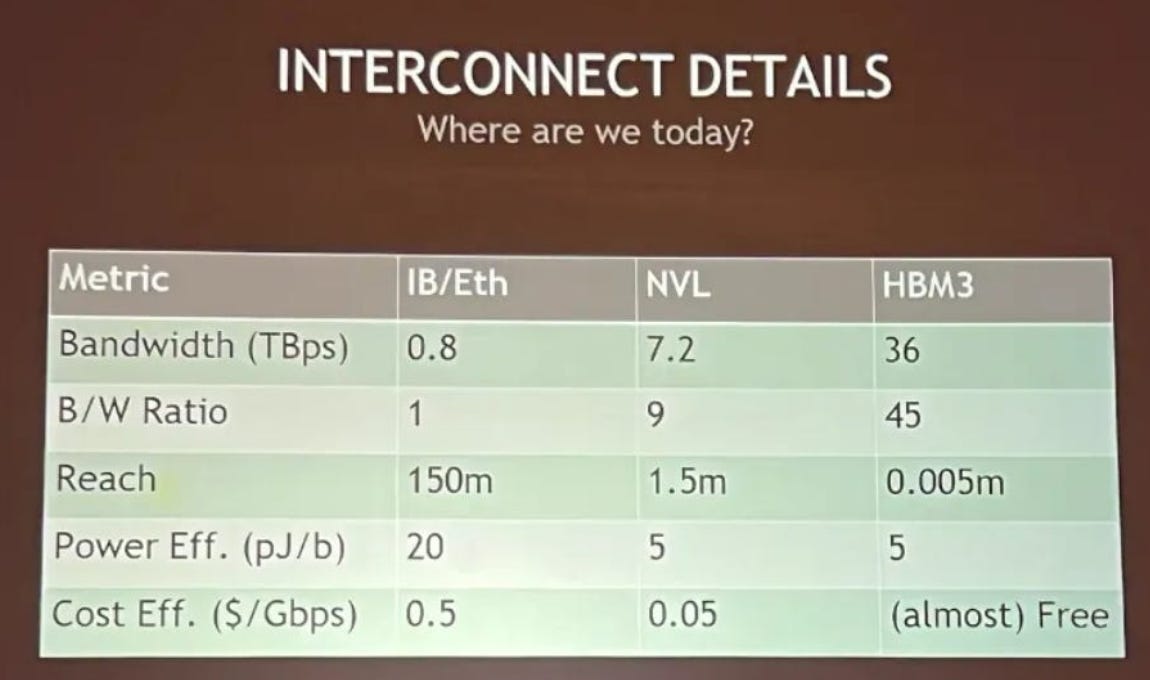
与连接多个GPU,还不如先把GPU做大些,HBM对应变大,带宽就是不要钱的了。HBM的瓶颈是CoWoS,最近有两家创业公司Eliyan和Celestial AI都在做这块,解决所谓的memory wall问题。

如果这一层做满了,下面就是NVlink这一层。PCIe现在是明显落后的,短期也追不上。下面是Jensen对NVlink的看法,非常重要。
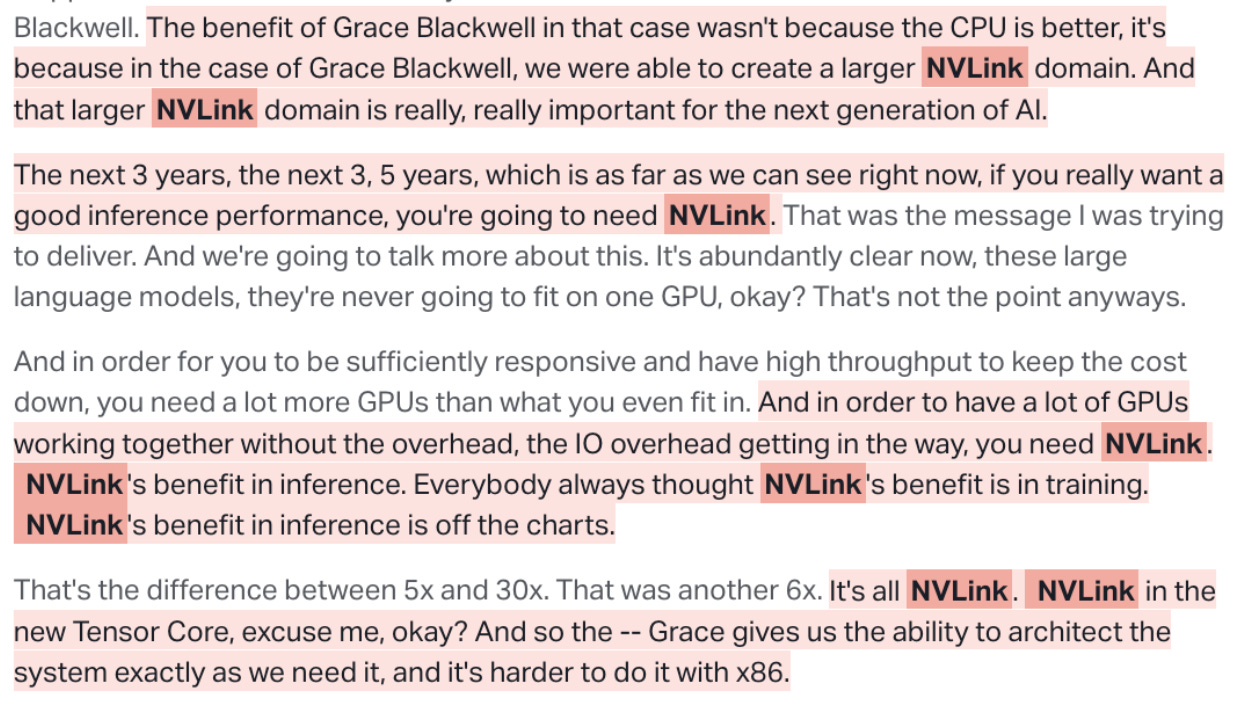
创业公司Lightmatter在融资,AMD和AVGO在研发Infinity Fabric。
最后第5层才是传统的网络层面,这里面的优化主要集中在干掉DSP,节省成本和耗电。基本上都是NVDA和AVGO在带头研究。感觉很难长期看好MRVL。
总结,NVDA目前优势很大,HBM需求强劲。
Holdings
继续持有APP。
AMZN在周四回调的时候被stop out,low conviction idea很难赚到钱。